96% Crash Reduction
How we transformed a crash-prone 50+ device mobile fleet into a stable, observable platform through systematic reliability engineering, queue-based architecture, and gated CI/CD practices.
The Problem
A mobile fleet plagued by crashes, flaky tests, and no quality gates.
Constant Mobile Crashes
50+ device fleet experiencing frequent crashes with no visibility into root causes, impacting customer-facing transactions.
Unreliable EPOS Printing
Point-of-sale printer communication failing intermittently, causing transaction delays and support escalations.
No Quality Gates
Code shipping without automated testing or manual QA sign-off, introducing regressions with every release.
Flaky Test Suite
Existing automated tests failing randomly, eroding confidence and slowing deployments.
Our Approach
Systematic reliability engineering across code, testing, and deployment.
Crash Analytics & Observability
Integrated crash reporting across the entire device fleet with real-time dashboards and alerting.
Queue-Based EPOS Architecture
Refactored Kotlin EPOS SDK communication to use reliable message queues, eliminating race conditions and dropped print jobs.
Gated Pull Requests
Implemented PR gates requiring both automated test passes AND manual QA approval before merge, even while building out automation.
Test Deflaking Pipeline
Built automated deflake detection that quarantines flaky tests and requires fixes before they block the pipeline.
Visual Evidence
Screenshots from the actual implementation.

Queue-Based EPOS Communication
Kotlin coroutines and message queues handling async printer operations reliably.
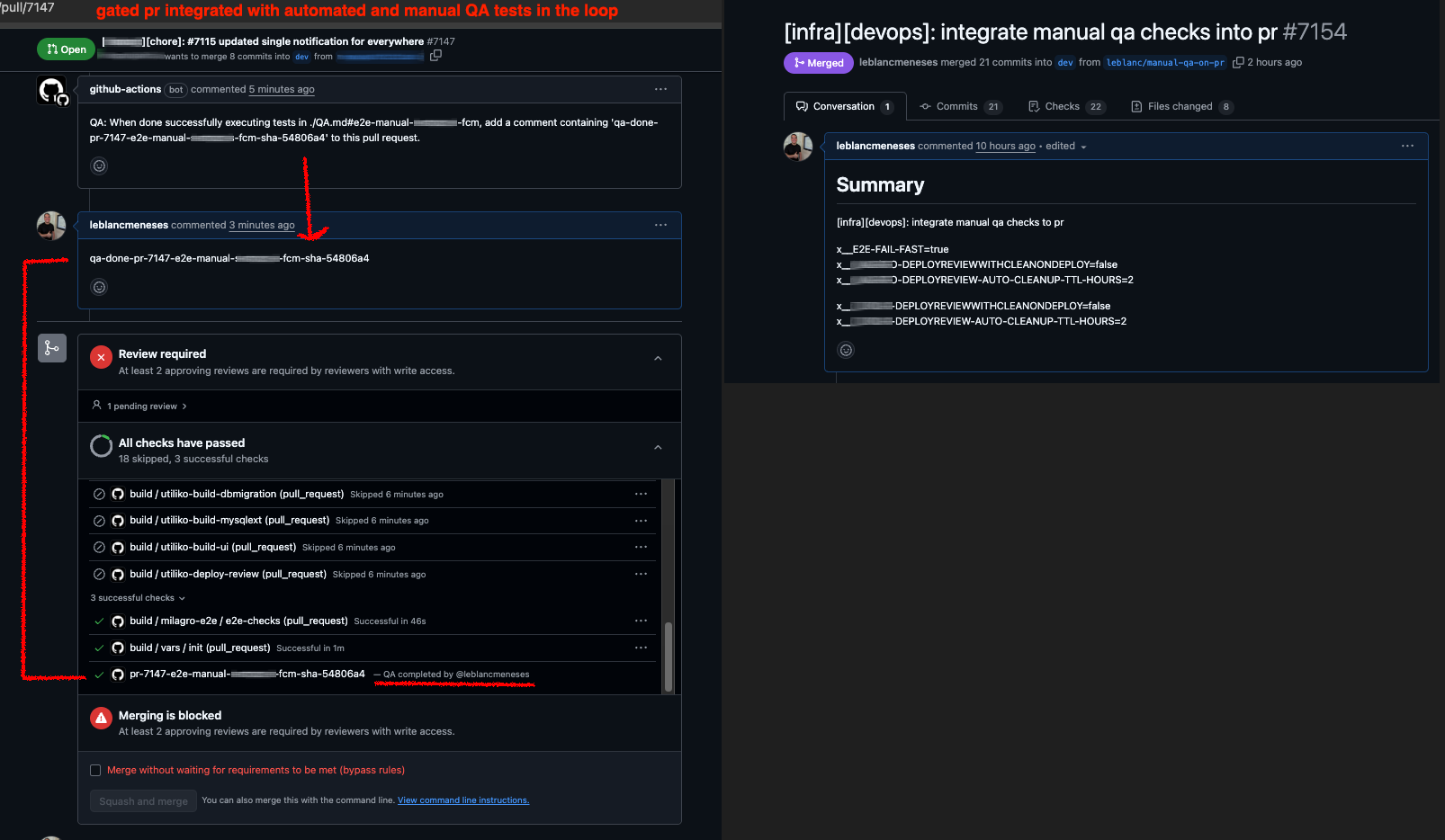
Gated PR Workflow
Manual QA approval gates integrated directly into the pull request process.
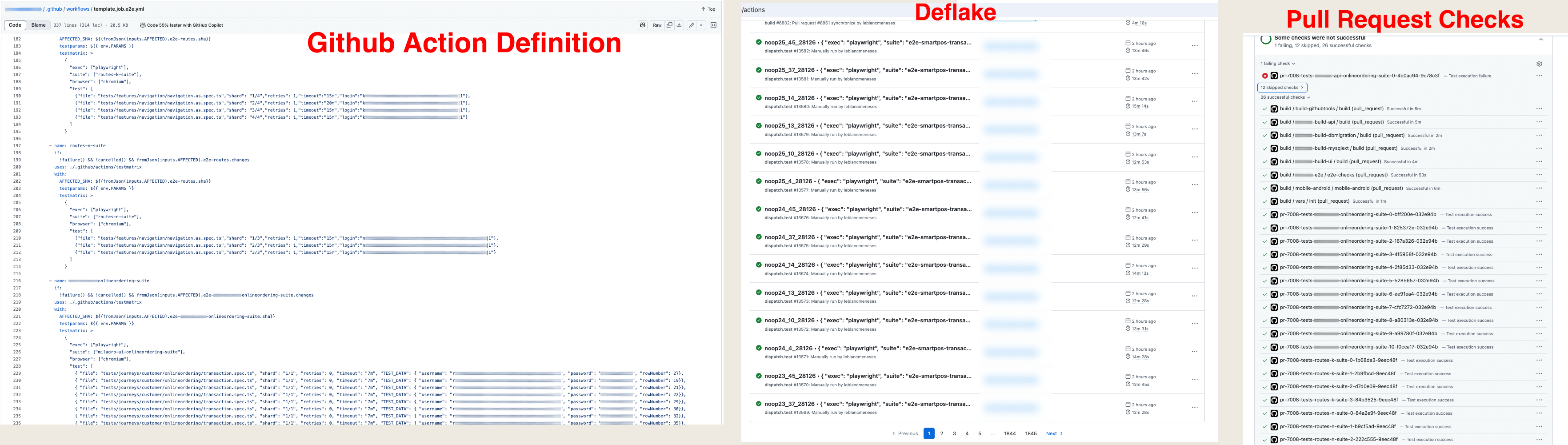
Test Deflaking Pipeline
Automated deflake detection quarantining flaky tests before they block releases.
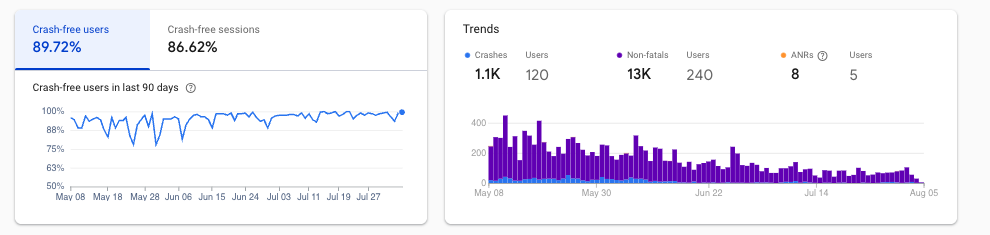
Crash-Free Users Metric
Dramatic improvement in crash-free user rate after interventions.
The Results
Measurable reliability improvements across the board.
Crash-free user rate improved dramatically
Full fleet visibility and stability
Every PR gated by quality checks
Deflaking process keeps suite reliable
How We Did It
A systematic approach to reliability engineering.
Assessment & Instrumentation
Audited crash logs, identified top crashers by device type, integrated Crashlytics across fleet, established baseline metrics.
Architecture Fixes
Redesigned EPOS printer communication with Kotlin coroutines and message queues to handle async operations reliably.
CI/CD Hardening
Added required PR checks for automated tests, integrated manual QA approval gates, built deflake detection into pipeline.
Continuous Improvement
Created dashboards for crash trends, automated alerts for regressions, established runbooks for common issues.
Why E2E Test Projects Fail
Missing any of these steps begins a downward spiral where business value becomes unattainable.
Culture Resistance
Dev team must take ownership of tests and continue development as new features are created. The organization must commit to change.
No Senior Bridge
Lacking a senior member to bridge dev and testing goals who can make required code changes to facilitate E2E testing.
Poor Infrastructure
Handicaps test engineers and negatively affects deflaking efforts. Sharding and parallelization should not be an afterthought.
No Hermetic Setup
Required to guarantee tests are repeatable and deterministic. Without it, false positives erode trust.
Bad Page Objects
Improper page object implementation leads to a skewed API that limits negative test implementations.
Weak Code Review
Not having strict code review process to enforce quality requirements leads to accumulated technical debt.
Business Value of E2E Testing
When done right, E2E testing delivers measurable business outcomes.
Early Detection
Capture bugs during PR validation. The longer you wait to detect issues, the costlier it gets once in production.
Integration Safety
Detect integration issues while upgrading third-party packages or during large system refactoring.
Critical User Journeys
Focus on realistic user scenarios that span multiple system boundaries and should never break in production.
Faster Time-to-Market
By detecting issues early, reduce time spent on bug fixing and rework, accelerating the development process.
Open Source CI/CD Resources
Reusable GitHub Actions for test orchestration and deployment pipelines.
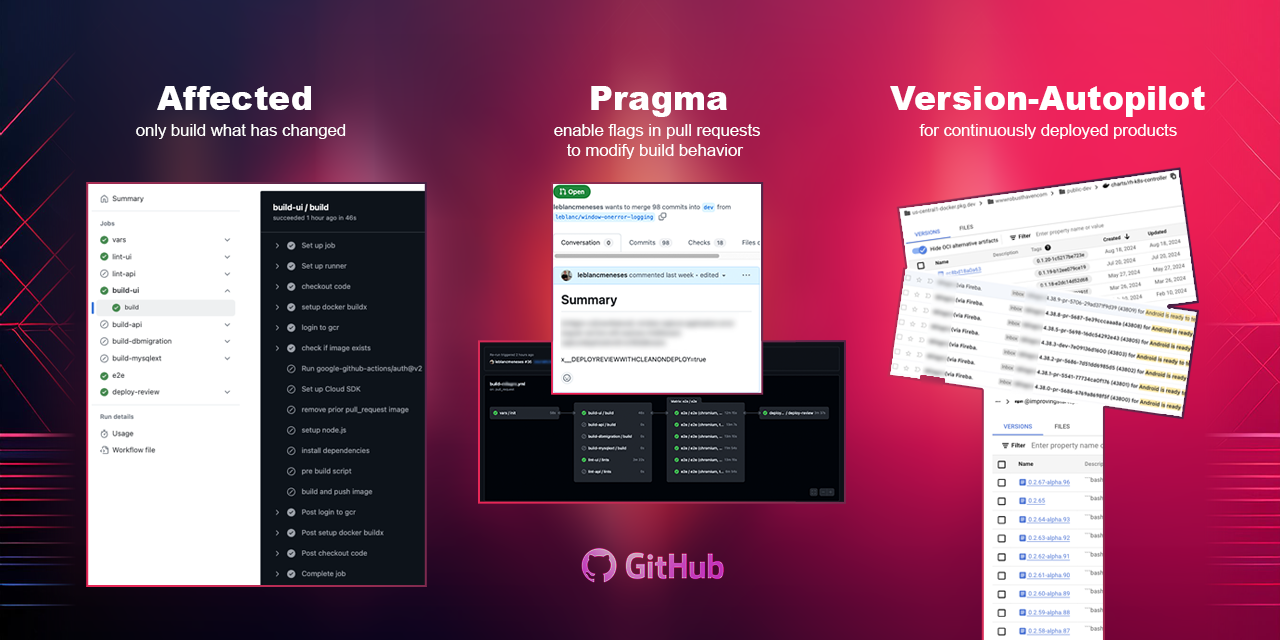
leblancmeneses/actions
A collection of battle-tested GitHub Actions for hermetic test environments, sharded test execution, deflake detection, and CI/CD pipelines. Used in production across web and mobile projects.
View on GitHubDeveloper Feedback on Environment Setup
Hear from engineers on how the K8s platform engineering solution transformed their workflow.
Why Most Teams Struggle with Reliability
Common patterns that hurt release quality and how to fix them.
Ready to Improve Your App Reliability?
Every platform has unique challenges-mobile, web, browser extensions, IoT. Let's assess your current reliability posture and identify quick wins.